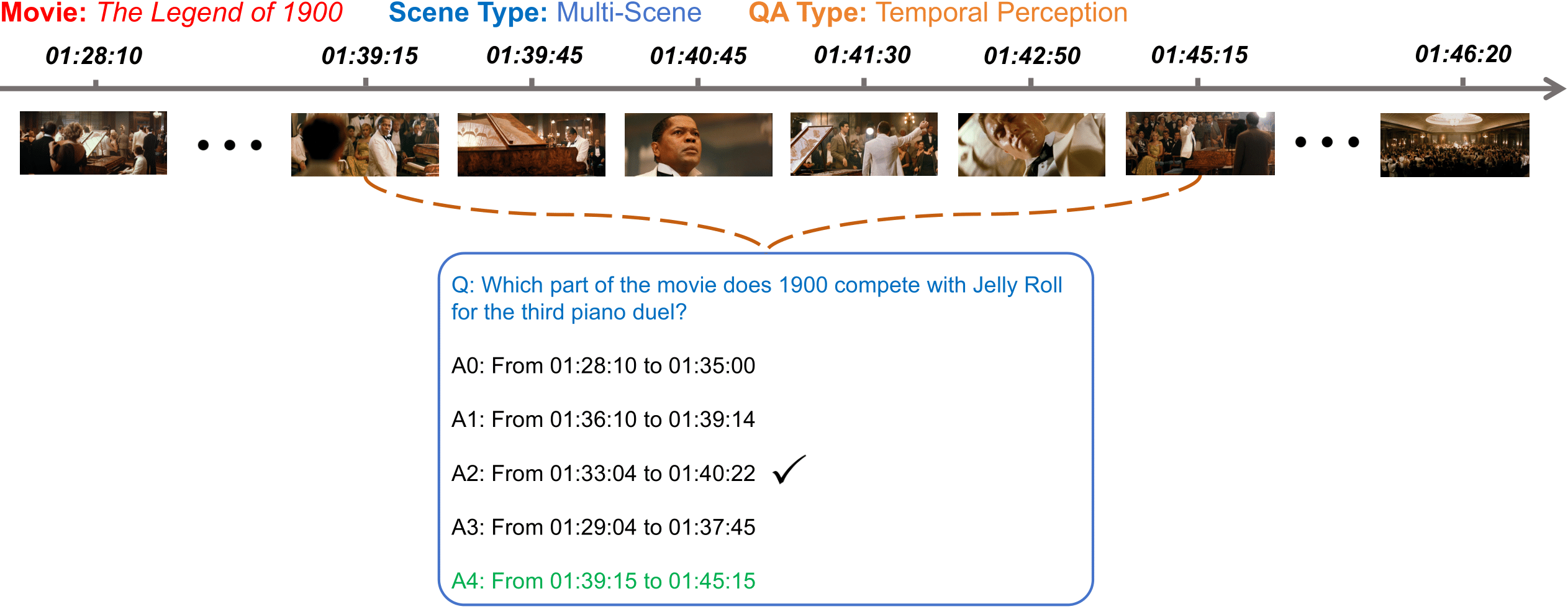
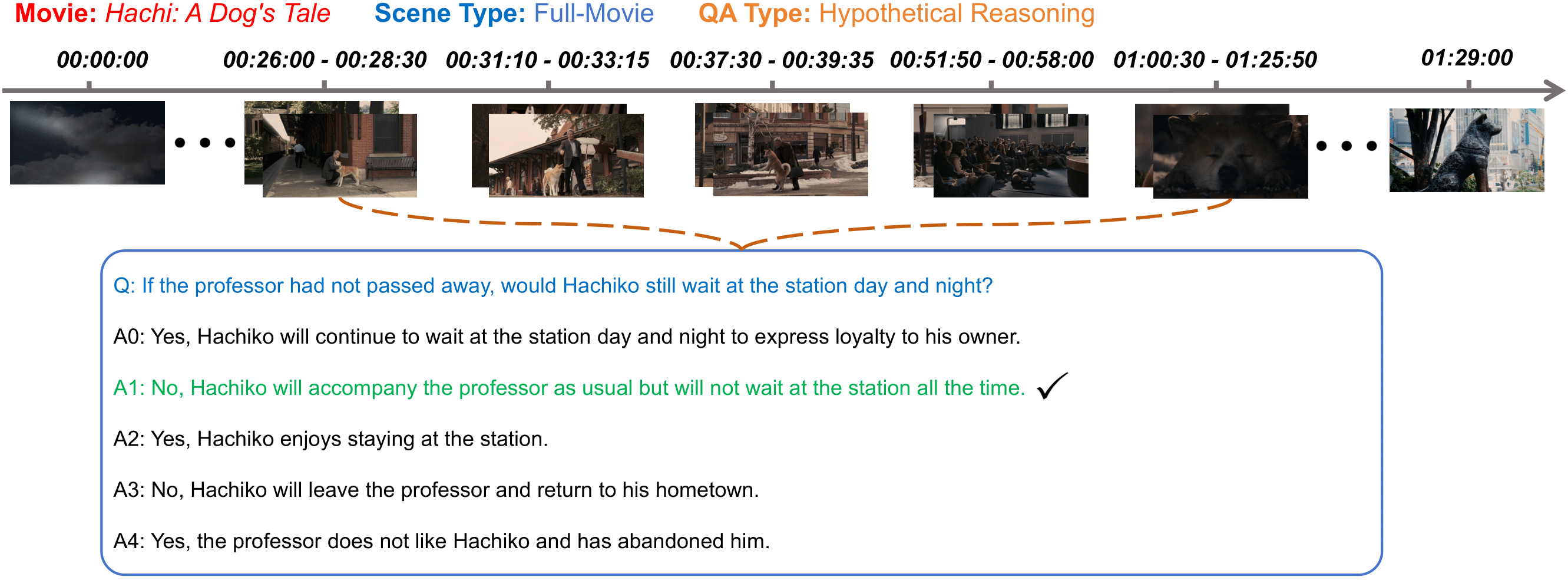
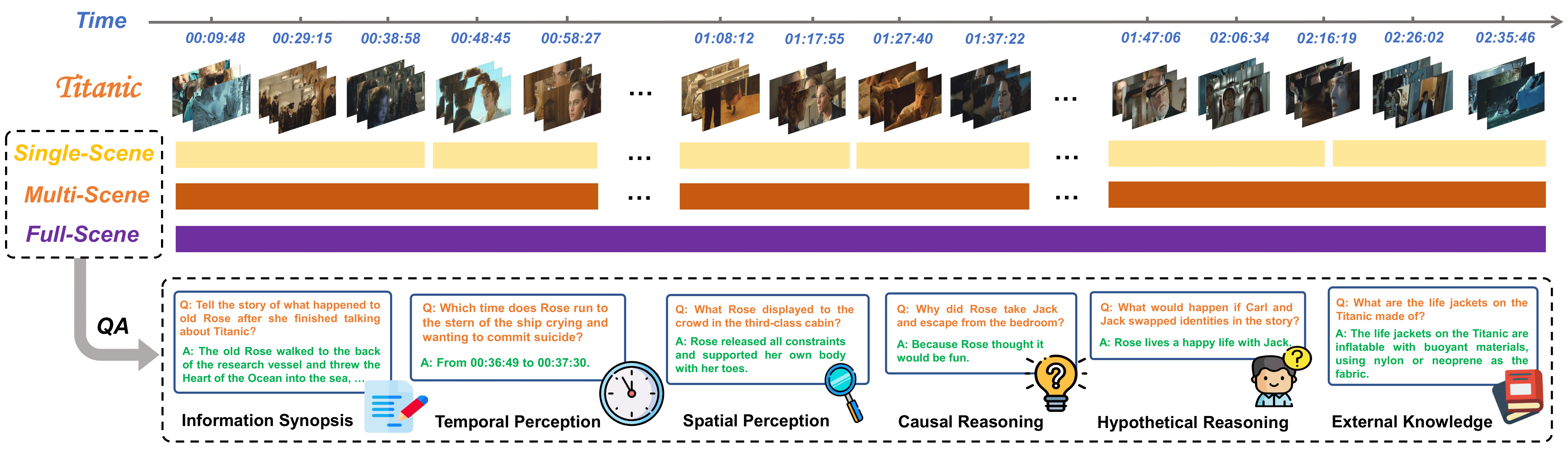
While several long-form VideoQA datasets have been introduced, the length of both videos used to curate questions and sub-clips of clues leveraged to answer those questions have not yet reached the criteria for genuine long-form video understanding. Moreover, their QAs are unduly narrow and modality-biased, lacking a wider view of understanding long-term video content with rich dynamics and complex narratives. To remedy this, we introduce MoVQA, a long-form movie question-answering dataset, and benchmark to assess the diverse cognitive capabilities of multimodal systems rely on multi-level temporal lengths, with considering both video length and clue length. Additionally, to take a step towards human-level understanding in long-form video, versatile and multimodal question-answering is designed from the moviegoer-perspective to assess the model capabilities on various perceptual and cognitive axes. Analysis involving various baselines reveals a consistent trend: the performance of all methods significantly deteriorate with increasing video and clue length. Meanwhile, our established baseline method has shown some improvements, but there is still ample scope for enhancement on our challenging MoVQA dataset. We expect our MoVQA to provide a new perspective and encourage inspiring works on long-form video understanding research.